WhatsApp- The Covid-Relief Helpline
A Case Study in Information Management on Chat Apps 26 June 2021
- Tarunima Prabhakar
- Swair Shah
- Denny George
Acknowledgements
Layout and Design
Saakshita Prabhakar
Executive Summary
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Vestibulum in euismod felis. Vivamus mollis leo in pharetra varius. Quisque tincidunt posuere diam at ornare. Donec tempus blandit risus, eu suscipit dolor tristique quis. Fusce blandit tempor arcu lacinia gravida. Aliquam erat volutpat. Donec aliquam malesuada ornare. Donec sit amet risus mattis, porta neque at, semper ipsum. Etiam velit est, tincidunt non congue non, pulvinar et quam.
Mauris suscipit sed diam eget sodales. Aenean laoreet ac turpis ut maximus. Vestibulum dapibus imperdiet imperdiet. Fusce est tellus, lobortis a efficitur et, consectetur volutpat eros. Aliquam erat volutpat. Curabitur accumsan dui egestas felis mollis, in pulvinar lectus commodo. Etiam auctor consequat purus, et finibus ante posuere quis. Curabitur egestas, tortor nec luctus blandit, ex leo iaculis lectus, rhoncus vestibulum elit odio et massa. Donec non porta neque. Sed vehicula odio est, a tempor risus laoreet eget.
Nunc dolor ligula, euismod eu placerat sit amet, tempus sit amet magna. Mauris egestas turpis sed gravida porttitor. Fusce mollis porttitor placerat. Mauris pulvinar convallis urna in congue. Nulla a odio ut neque porttitor facilisis a sed diam. Vivamus in vestibulum urna, vel consectetur metus. Praesent non nulla eleifend, aliquet risus eget, suscipit quam. Integer accumsan eros in lacus tristique auctor. Suspendisse sagittis tempor quam non congue. Cras egestas bibendum leo, quis ornare felis accumsan in. Nam ut leo id erat venenatis tincidunt viverra vitae ipsum. Mauris diam ante, pellentesque in tellus et, ultrices auctor ipsum. Mauris non ornare mauris, et accumsan nibh. Donec dictum eleifend velit, ac bibendum urna porta suscipit. Ut nibh tortor, sagittis id viverra vel, ullamcorper sed lacus. Vivamus fringilla placerat risus.
In accumsan dui urna, id mattis eros ultricies non. Nullam sed ligula ante. Sed suscipit fermentum diam sit amet eleifend. Nunc ac elit iaculis sapien vestibulum posuere nec ac augue. Donec nec enim nec urna egestas finibus. Quisque eget nulla sit amet mauris vehicula venenatis. Duis sed enim nunc. Vestibulum elementum pretium nulla, sit amet consequat nibh malesuada ut. Vivamus ornare hendrerit sapien, sed suscipit nulla rhoncus in. In placerat lectus id felis bibendum auctor. Curabitur id molestie mauris. Pellentesque feugiat augue vel libero tempus, non porttitor est tempus.
The Need for Relief Work in India’s Second Wave
When the second Covid-19 wave hit India in April 2021, the demand for oxygen concentrators and cylinders, medicines, hospital beds and plasma donors exceeded the capacity of public and private health service providers. The crisis first hit the metropolitan cities of Delhi and Mumbai, but was soon felt in other parts of the country.
A year into the pandemic it was clear that timely care was critical in Covid treatment. But as cases rose exponentially, health facilities faced an unanticipated and incomparable burden. In the capital city, New Delhi, any available hospital bed had many takers. The status of availability of beds in hospitals changed rapidly and government provided dashboards were not updated frequently enough. People who headed to a hospital based on some information, were turned away since the vacant beds were occupied by the time they arrived to the hospital. As the city started seeing shortage of medical Oxygen, hospitals stopped intake of patients to optimize for their reserve Oxygen. Consequently, leads for hospital beds in the city or neighboring cities, or for medical Oxygen became critical information. When the usual channels such as government helplines, neighborhood hospitals and pharmacies became unhelpful, patients or their family and friends began to reach out to their networks for help.
Those who were on social media platforms, broadcast requests on platforms such as Twitter, Instagram and WhatsApp. On Twitter, requests were noticed and amplified by political representatives and celebrities. The heightened demand also created black markets for medical resources. It also resulted in scam operations. Several advertisements by oxygen cylinders and concentrators turned out to be fraudulent. Since patients and their families were in isolation at home, or geographically distant from the providers, they relied on providers to deliver medical supplies. By requesting for a payment ahead of delivery, scamsters duped patients by taking the money but not delivering the medical supplies. People lost money and critical time in Covid care.
The proliferation of scam operations and the pace at which leads became irrelevant resulted in a need to verify leads. Motivated Individuals, neighborhood communities, religious organizations, corporate social responsibility groups took the role of intermediaries, connecting patients and their families to ‘verified leads’ for hospitals, Oxygen, medicines and plasma donors. While some volunteering groups were operational since the first wave of the pandemic in March 2020, the second wave led to spontaneous organizing for Covid relief. Many of these groups focused on medical needs but some also focused on providing food to patients, frontline works and to those who had lost their livelihoods in lockdowns. An Indian news outlet captured the role of social media in an article headline “How volunteers have made social media the national Covid ‘helpline’ for beds, oxygen, plasma?”1
Twitter and Instagram became platforms to broadcast requests and leads and WhatsApp emerged as a crucial platform to organize volunteering energy.2 The group chat feature on WhatsApp allowed for creation of functional boundaries within which similarly intentioned individuals could coordinate efforts and triage information. The WhatsApp group delineated a space with informally specified procedures and protocols, enforced by loose social and technical hierarchies. Even if the feature was not used, group chats allowed for exclusions of norm-breakers by group admins.
With over 400 million users, WhatsApp is the most widely used app and social media platform in India3. As per one estimate, over 90% of internet users in India aged 16 to 64 use chat apps.4 As per Lokniti’s 2019 survey on social media and political behaviour, even though WhatsApp’s user base is skewed towards younger demographics, it is the most widely used social media platform across age groups. In 2019, 19% of respondents in 46–55 age group claimed to be daily or weekly users of WhatsApp. This is a stark contrast to Twitter where only 7% of respondents across all age groups were regular Twitter users.
Even though WhatsApp only allows groups of 256 individuals, the high adoption makes it the obvious choice for spontaneous organizing. One feature of Covid relief is that it is regional. Patients need resources in the cities/towns that they are living in. Lockdowns and restrictions are implemented locally based on the severity of the outbreak in a district or state. Covid facilities are largely managed by states. Finally, verifying leads and connecting patients to medical resources could require familiarity with regional languages.
Since volunteering groups might be seeded by a group of individuals who are geographically co-located and know each other in person, it is natural for them to adopt WhatsApp as a platform for coordination. Furthermore, WhatsApp remains the most accessible social media platform for Indians. To sidestep the group size limitation, a volunteering community may run multiple WhatsApp groups, with some admins common across the groups. Furthermore, while WhatsApp isn’t designed as a platform for broadcasting information, volunteering groups providing assistance or in need of volunteers, have to broadcast information about their existence to be discoverable by broader public. For this purpose, group admins may advertise the links to join these groups on more open platforms such as Twitter or on a volunteering website.
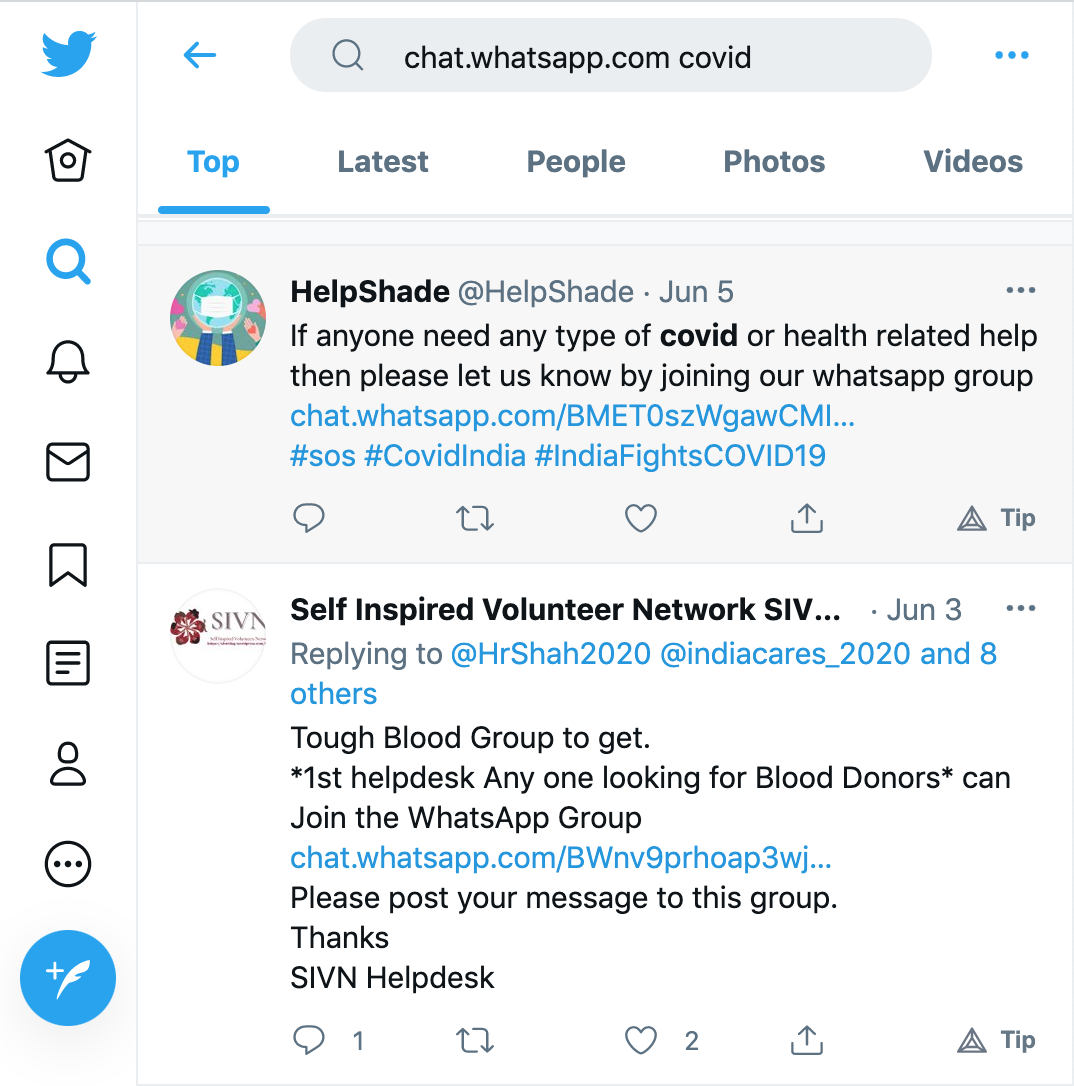
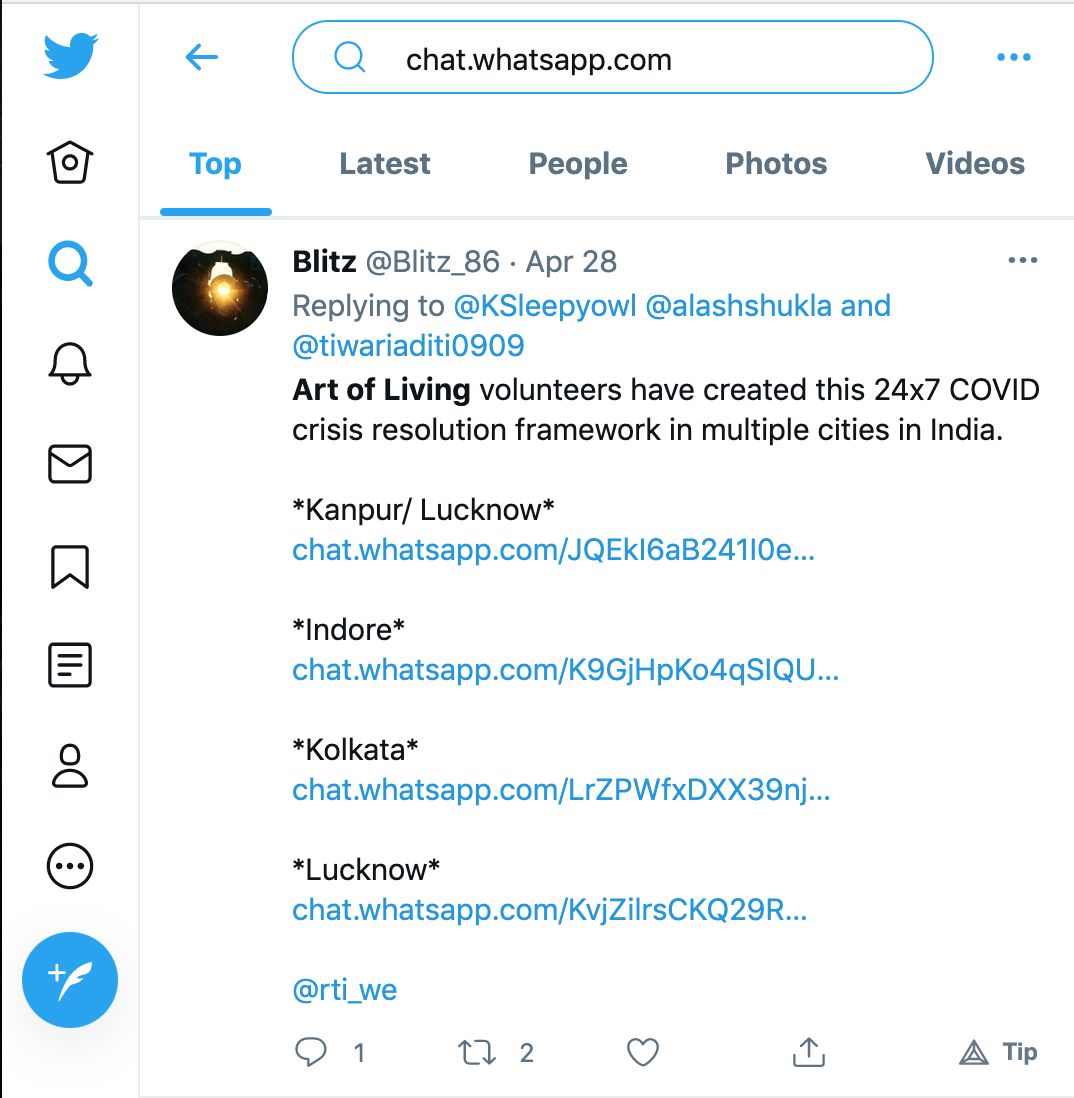
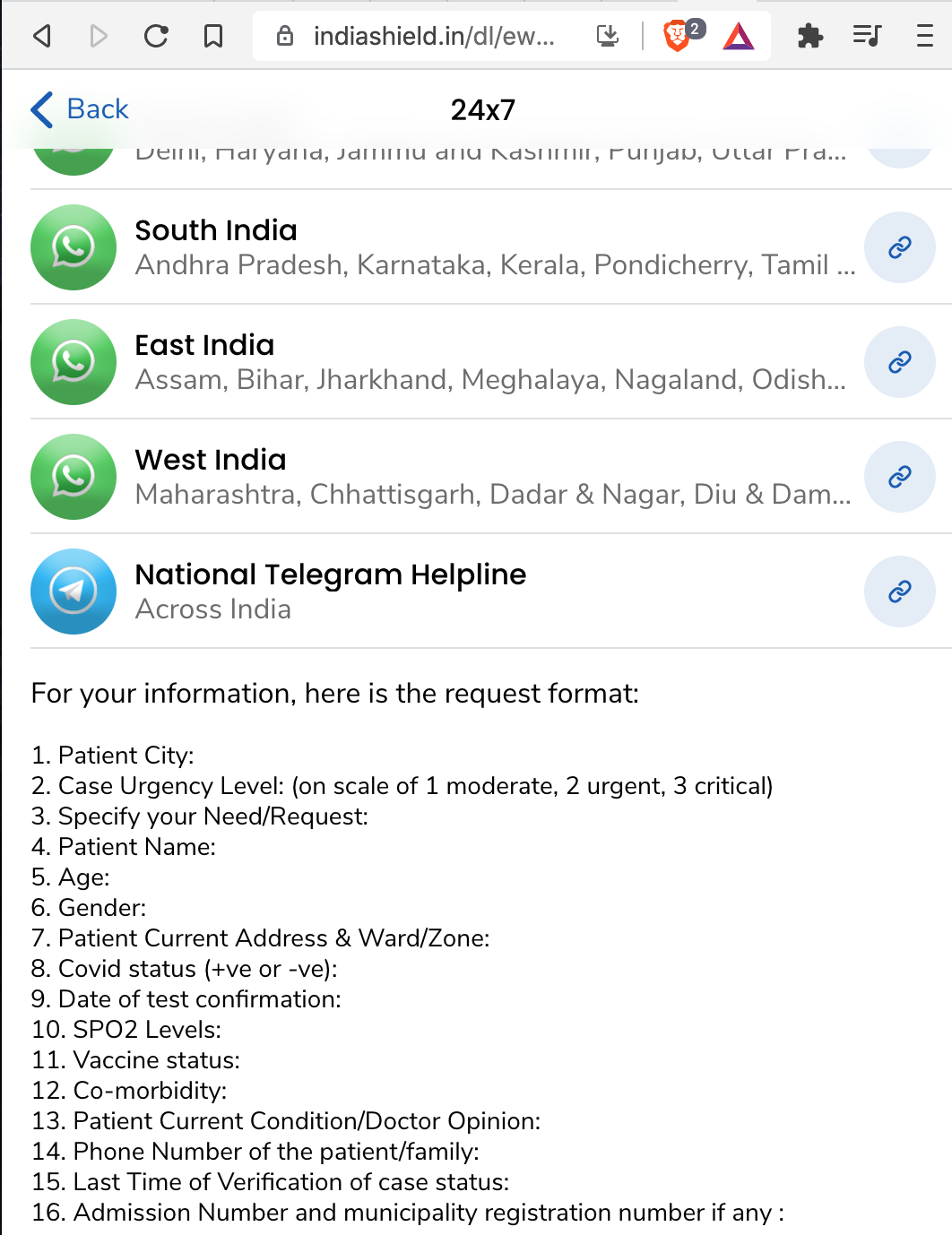
As figure 1 shows, volunteering groups connecting patients to resources on closed messaging apps such as WhatsApp, converged on processes and information formats to make relief work more efficient. These processes emerged since the nature of aid requested during the second wave were similar. When requesting for plasma it was important to know what Blood group was being sought. The level of medical support needed by a patient depended on their SPO2 levels and co-morbidity.
The format in which information was requested, however changed depending on the volunteering group and the medical need. In coordinating plasma donation, patients’ blood group type was needed. When requesting Oxygen support, people often shared their home address. While the patient or the immediate family members of a patient might not be on WhatsApp group helplines, people in the extended networks who receive such requests may post it in these groups looking for resource leads. These requests were also shared on more open platforms such as Twitter, Facebook and Instagram. The qualitative difference between messaging apps such as WhatsApp and open platforms such as Twitter is that information cascades on Twitter are caused primarily by retweets and can be controlled to some extent by deletion of posts by the original creator or by the platform. Messaging apps might allow a grace period (one hour for WhatsApp) during which the sender can delete the message for all the receivers and senders. But on the whole, WhatsApp doesn’t allow for retrospective edits of messages. It only allows for additional context to be added to a message through the reply to message option. The message once sent resides on the phones of all those on the group who have received a message.
Why Study Covid Relief Groups?
“What we really need to do to design is look at the extremes... Because if we understand what the extremes are, the middle will take care of itself.”1 Rise in popularity of messaging apps for individual and group communication has gone hand in hand with an increase in inaccurate, harmful and low credibility information on these platforms6. In 2018, lynchings in India were connected to rumours circulating on WhatsApp. Understanding how chat apps are used for coordinated messaging and how harmful ‘viral’ content can be addressed on platforms without centralized moderation, has assumed urgency over the last few years. Prior research on messaging apps tended to focus on political misinformation7, especially around elections89. The pandemic has led to renewed interest in countering health misinformation. In health emergencies, uncertainty is inevitable.10 The anxiety accompanying uncertainty, and information voids11 make health emergencies especially fertile events for mis/disinformation.
The second wave in India became an emergency within a public health emergency. The death toll rose rapidly and reports of deaths of fully vaccinated individuals, health practitioners12 and younger demographics13 spread panic about the double mutant, later named the Delta variant. Even as more people tested positive, the course of treatment became less clear. Protocols developed in the preceding months were tested. Medicines were in short supply. Eventually, in cities like Delhi, medical Oxygen too ran short. Even as patients were being prescribed by convalescent plasma therapy, doctors on social media dissuaded this course of treatment14, except in specific cases.
Misinformation around Covid cures has existed through the pandemic; in the second wave the misinformation tallied with prominent themes of the crisis such as Oxygen treatments.15
The second wave, however, introduced another unprecedented form of information crisis, by creating demand for a specific kind of information. In the crisis, a lot of people were simultaneously looking for information, such as leads for Oxygen suppliers, hospital beds and plasma donors, that was immediately actionable. This is in contrast to the usual typologies of misinformation that aim to shape opinions or affect a long term decision. Another contrast is that this information sought was local or hyperlocal- people needed leads in their vicinity. There was no reliable centralized source for such immediately actionable information.


In the short term, the supply of medical resources couldn’t change. The number of people in need exceeded the resources available. There weren’t enough leads for all those in need. Noisy information, leads that were old or fraudulent, began to fill the deficit. Medicines or hospitals, became unavailable within minutes of signal of availability. This status of any specific lead changed rapidly. It is hard to imagine many other scenarios in which actionable information for city scale population changed as rapidly. Regardless of whether a message was viral or not, if it was old or inaccurate, it was imminently harmful.
Arguably, inaccurate or obsolete leads, should not be characterized as misinformation. Fraudulent leads, at least, are better labeled under the more specific category of online scams. The term misinformation, while broad and flexible in definition, has been used primarily to describe content aimed at changing people’s perceptions.16,17 The term emerged from academic discourse to mainstream parlance to describe the phenomenon of ‘fake news’.18 The rise in user generated content has pushed the definition of the term beyond ‘news’ typified by a source, website or renowned media channel. Some attributes of ‘fake news’ such as linguistic features and network of dissemination extend to messages typically viral on WhatsApp.19 But, short messages, providing phone numbers for medical resources aren’t captured even in this bucket of WhatsApp like content. The only purpose of these leads is to provide contact details of suppliers, who are (reasonably) assumed to be the source of the information. Message attributes such as grammatical mistakes, don’t bear on the quality of the information itself. The primary purpose of sharing requests for help on social media and messaging apps is to look beyond one’s immediate networks- one is proactively seeking information from strangers. This also reduces the utility of networks of dissemination in judging credibility of these messages.
Messages with leads, however, have several attributes in common with more prototypical misinformation. These leads cause harm because of inaccurate information. The lead might have been inaccurate on the date of creation of message (with the intent to scam), or might be inaccurate on the date of receipt (information is obsolete and not actionable).20 These messages demand similar kinds of interventions by platforms, governments and citizens for suppression of low-quality information, as more news-like misinformation. If we look specifically at fact checking- these messages leads are legitimate objects of verification, and are subject to similar verification processes as more news-worthy social media content. In the past, Fact Checkers have verified phone numbers circulated on social media and provided them with a ‘Fact-Check’ status label such as False or Misleading.21,22Such verification work became customary during the second wave- one fact-checking group in India created a dedicated section listing the Covid aid leads they had verified.23
The category of messages describing local resources for medical aid serves as microcosm with the information ecosystem, where several aspects of the misinformation challenge are heightened. There is an excessive demand for information; anxiety and uncertainty further drive consumption of this content; inaccurate information is indistinguishable from relevant and actionable information; and people must find credible information despite accurate and actionable information becoming obsolete in minutes.
A message on WhatsApp comes with no information about when it was created or who created it. Both these data points, the source and the time of creation, serve as important context when trying to gauge the relevance of specific information for relief work. An update about the status of availability of hospitals in a city from two days ago is likely to be obsolete and unactionable. In absence of the source or time-stamp, what markers and processes did people seek or fall back on to gauge credibility? How were rapid updates about specific messages communicated through messaging networks? How quickly, if at all, did inaccurate content fade from these networks? Understanding the answers to these question in this specific context could shine a light on the broader phenomenon of misinformation on chat apps.
A second motivation of studying these groups was to broaden the understanding of emerging online publics. As highlighted in the previous section, these WhatsApp groups became a means for community organizing and consequently public engagement during Covid relief. Messaging apps exemplify the blurring of distinctions between public and private spaces online. These apps are designed to be private yet social communication platforms. The simultaneous existence of private and viral content on the same platform not only presents challenging questions about the form of communication, but also about how to understand what is happening in these spaces. One model of research is to identify and join groups that can be assumed to be reasonably public, and analyze the conversations in these spaces. If an invitation to join a group (through group links) is broadcast on Twitter, it is reasonable to assume that the group administrators aimed for it to be discovered by (some) strangers. Specifically, messaging groups created exclusively to coordinate information and aid for those affected during the pandemic serve a public purpose. Yet, the nature of relief work during the second wave meant that a lot of private information about individuals was being shared on these WhatsApp groups. Such information was also shared on more open platforms such as Twitter, Facebook and Instagram. But this content could be taken down by the user or a platform. Many people did delete tweets where they were requesting for help for other individuals. On WhatsApp, on the other hand, a user had no control over the message once it has been sent out.
To summarize, the motivation of this study is two pronged:
To understand how, if at all, risks from identification of specific individuals through details shared in seeking or offering assistance were managed in Covid relief groups.
To understand how information is sought, shared, triaged and updated in a rapidly changing information environment.
What Are The Documented Harms?
In this section we try to explain what is at stake when low quality information proliferates in spaces with blurred public and private boundaries. We document harms to individuals from being identified on and through these groups, as well as harms from inaccurate and obsolete information. These harms are not unique to information shared through chat apps. However, the storage of communication in device end points (mobile phones) as opposed to centralized servers, demands a different approach in responding to harms on chat apps.
Harms from Identification of Individuals
In requesting for assistance, or in volunteering, individuals shared their phone numbers on messaging apps and social media platforms. The goal of broadcasting such information, was to reach outside one’s immediate networks. This broadcast, however, also exposed their phone number, name and other details for unintended uses.
Harassment of individuals based on gender, religion and other identifiable attributes.
On Twitter, several women reported receiving sexually explicit messages and calls after sharing their number for seeking Covid resources for family and friends.24 Volunteers who shared their number were also similarly harassed25. In Bangalore, after a local political leader singled out sixteen Muslim volunteers in a ‘scam’ at the city’s Covid response helpline, the list of 205 volunteers working in that specific zone was circulated on WhatsApp26. Volunteers on the list were inundated with Islamophobic calls and messages.27 Not only did this hamper their ability to respond to calls on the helpline effectively, the harassment also led to psychological stress.
The strong use of digital tools in accessing and coordinating relief work implied that access to critical medical care was skewed towards those with digital and functional literacy28. Over 50% of India still lacks access to Internet. The targeted harassment, however, further restricted the group of people who could request or ask for help. Women reported relying on male members of the family for any social media outreach. The harassment places additional burden on friends and family of patients or volunteers, stealing critical time away from care-giving responsibilities, and further hampers their mental health in a stressful situation.
Secondary Uses of Data:
When requesting for help, personal and possibly sensitive personal data of patients, such as medical history and neighborhood were divulged. This information was shared in addition to phone numbers or other contact details. Such information is ripe for telemarketing of Covid related aid during the crisis, and other products and services such as health or life insurance afterwards.
Harms from Inaccurate and Obsolete Information
Uncertainty of information is inevitable in a public health emergency such as a pandemic. Evidence around the pandemic is continually updated. Misinformation has been a feature of this pandemic since the very beginning.
The crisis became an opportunity for scamsters to exploit a desperate demand for medical supplies. The scam operations took money and did not have
Loss of time Timely care can be the difference between life and death in Covid-19 response29. During the second wave in India, medical resources were not available through the expected formal channels such as hospitals. As hospitals ran out of drugs or Oxygen, patients and their care takers needed to find these critical medical resources against time. For every inaccurate or obsolete lead, patients lost more time in accessing critical care. Victims of fraudulent operations lost hours, and possibly days, waiting for oxygen supply.
Loss of money Scarcity of resources resulted in price hike of medical resources. The price of medical Oxygen increased by 700% during the two months of the second Covid wave in India.30 In black markets, the drug Remdesivir could cost five times its actual price.31 At its peak, the cost of an Oxygen concentrator exceeded the per capital income of an Indian32,30- many Indians spent an entire years’ earnings procuring a specialized medical device, because of the lack of availability of hospitals.
The desperation of patients and black markets created room for scamsters. People who paid for medical resources on the promise of future delivery, lost money equivalent to months’ worth of earnings or their entire life savings.
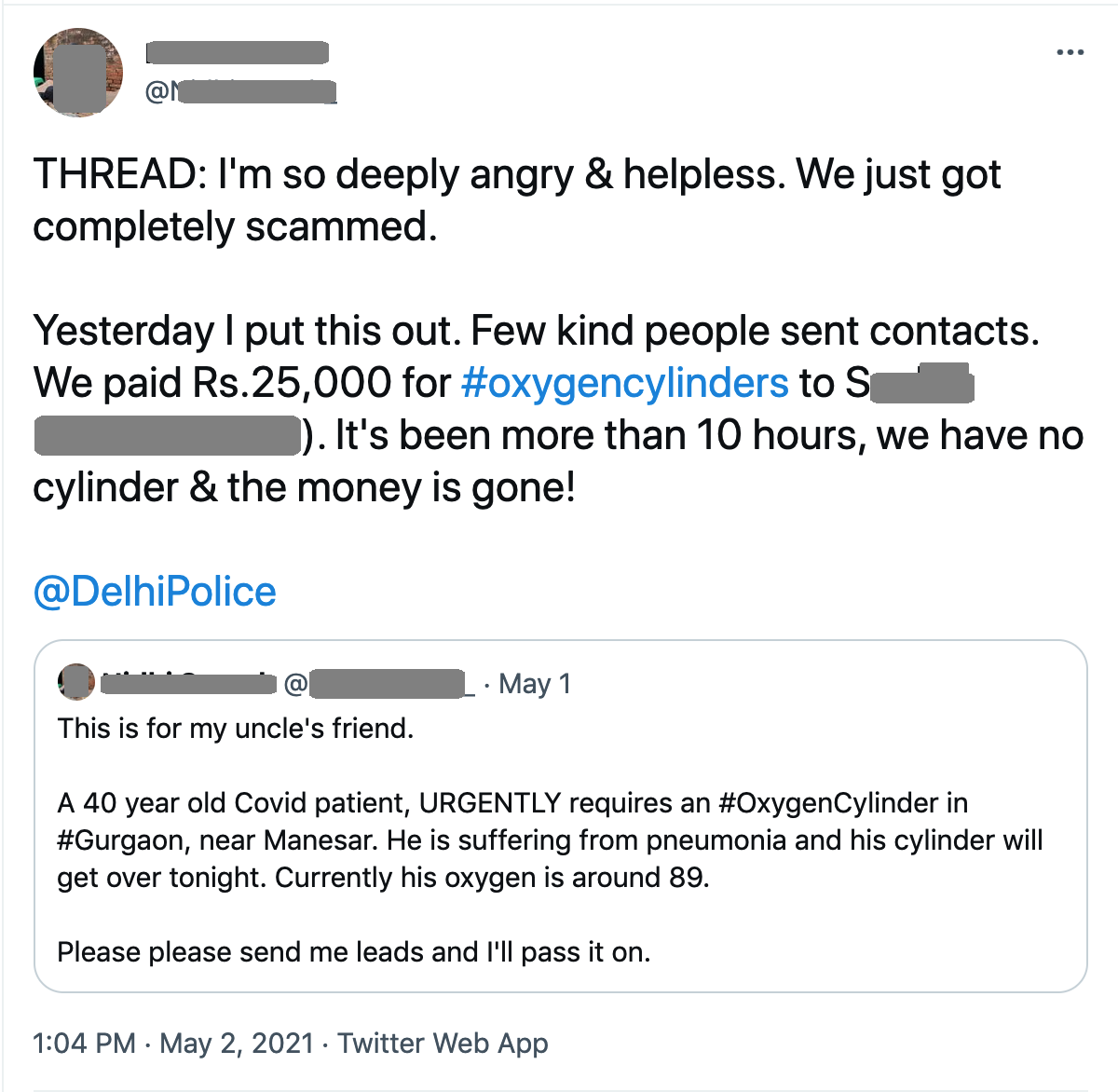
Loss of life
Since the beginning of the pandemic, the WHO had warned that misinformation could be life threatening.33 As per some estimates, at least 800 people may have died globally due to Covid related misinformation and thousands more may have been hospitalized.34 Misinformation around medical remedies were a feature through the pandemic. During the second wave, newer instances of misinformation around remedies emerged, that latched onto dominant concerns in the second wave in India. One video claimed that a nebulizer machine could be used as a substitute for Oxygen cylinders or concentrators.35
As previously mentioned, inaccurate and obsolete leads for medical resources led to delay in patients receiving critical medical resources such as Oxygen and drugs. This ultimately contributed to higher mortality from the disease.

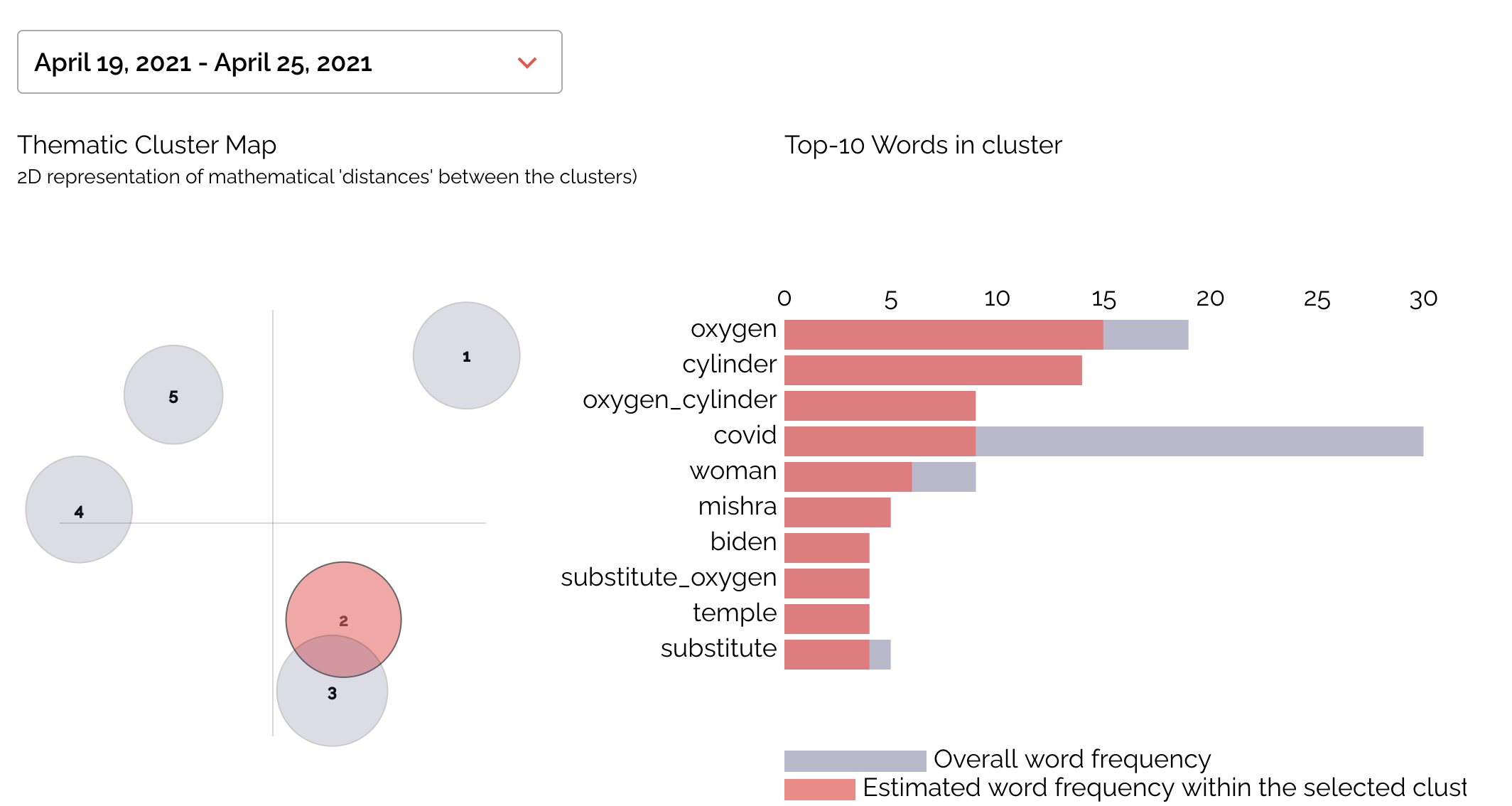
Data Collection
We joined eighteen WhatsApp groups on 29th April 2021. By this time, India was deep into the second wave of the pandemic. It still 10 days away from the peak (which hit on 8th May 2021). Cases in New Delhi, a state which saw acute shortage or medical Oxygen, had started declining. Cases in Maharashtra, another badly hit state, were also on a downward trend. As the pandemic spread to other parts of the country, volunteering energy spread beyond the main metropolitan centers.
We searched for WhatsApp group links shared on Twitter. Several of these groups had already reached the 256 limit, and we were thus unable to join them. Two groups had the ‘disappearing messages’ setting turned on. We took this to be an indication of intention to keep the communication on the group private and thus exited the groups immediately.
In the second phase of the study on June 9th, we searched for other Covid relief groups on Twitter. The number of such groups had declined but we identified and joined another five groups. By this time the total number of Covid cases had declined to numbers at the peak of the first wave. The central and state machinery had had the time to streamline their work. Joining these groups gave us the opportunity to see how relief work and requests had changed.
We have confined this analysis to an eight week period between 29th April 2021 and 23rd June 2021. From preliminary analysis, we realized that two groups in the first batch of groups we had joined (on 29th April 2021) were not Covid relief groups but were run by media organizations to exclusively share content from their organization. We exited these groups and excluded them from analysis. Thus, the final data that we analyzed came from a total of 21 groups, 16 of which we joined on 29th April 2021 and 5 of which we joined on 9th June.
We used two parallel approaches to move data from the mobile device to a cloud service through which data could be used for analysis. We used WhatsApp’s export chat feature to frequently back up the history of a chat on the cloud service. WhatsApp’s export chat feature results in a text file which contains the sender’s name/phone number, the time stamp of receipt and message content. WhatsApp claims that the export chat feature allows users to export 10,000 messages with media items and 40,000 messages with without media items36. In practice, the export chat feature fails to export media items or the text messages reliably. Many media items downloaded on the device are not exported, and the total number of messages exported is also inconsistent. In total, we used the ‘export chat with media items’ feature 61 times. The maximum lines in any text file exported were 4060. Exporting chat without media items was more reliable and captured most of the text messages. Excluding media items, however, is to exclude all multimedia related content which is a crucial part of WhatsApp conversations.
In order to make up for this discrepancy in data collected from exported chats, we used a complementary approach of saving the media items that were downloaded in the ‘WhatsApp Media Downloads’ folder. Although WhatsApp is supposed to automatically download media items it receives if the “Auto Download Media” setting is enabled, we were not able to reproduce this behavior on the Samsung Galaxy M10 we used. We resorted to manually clicking the media items to download them. We then backed up the media items download folder to a secure cloud service.
Since we were using one phone exclusively for the purpose of data collection from the Covid relief groups, the media items in the media downloads folder from this duration came only from these groups. Unlike the export chat feature, the media downloads folder does not provide information about the group or the time at which the media item was received. It however, captured over a thousand more media items than the export chat feature. To avoid repetition in media items, we discarded media items collected from the export chat feature for any media analysis and used media items only from the media downloads feature.
Analysis of WhatsApp Conversations
Over the eight week period we collected 7530 text messages, 2415 images (2296 unique). We also collected over 200 videos over this time, but we did not undertake any video analysis in this study.
At the time of joining, we were primarily targeting groups in English, Hindi and Marathi, since these are the languages understood by the team members. In addition, we also joined one group in Telugu. In the final sample of posts, we also found messages in Tamil, Telugu, Gujarati. For analysis, text in all languages was translated to English using a Google Translate API.37
Image Analysis Using Similarity Matching
We used a high dimensional representational embedding …. to cluster the images based on similarity. This similarity matching technique accounts groups based on visual similarity as well as semantic associations in the images. The clustering algorithm was run on the original images. The images were blurred and faces in images in the were obfuscated in the final visualization to prevent amplification of the leads. The appendix contains more details about the techniques.
The biggest cluster in this image cluster map is screenshots of posts from Twitter and Instagram. A scan of this cluster shows that majority of these screenshots are phone number and leads for Oxygen suppliers, drugs, hospital and ICU facilities and other medical supplies, indicating heavy reliance on other social media platforms for finding medical relief.
The cluster of web and mobile screenshot images is also similarly large. This cluster contains a greater diversity in the content of images- some are screenshots of WhatsApp and Facebook posts (f27a639d-6f89-4a46-a2fd-5073e1ccb19e.jpg). Some are screenshots of apps and websites with resources of Covid related information.
todo : insert social media image
The other big cluster is of medical prescriptions and receipts. These images could be attributed in part, to the need to show receipts to avail drugs, hospital beds and blood donations. People requesting for help were sharing detailed medical records to assert legitimacy and urgency of medical need. These prescriptions and receipts contain several personal details such as patient name, hospital of admission, blood group and co-morbidities.
Another reasonably large cluster is of images of medical supplies such as drugs, concentrators and masks. There are a number of images of the Amphotericin medicine boxes. Amphotericin is used to treat fatal fungal infections such as mucormycosis. Our data collection period coincided with the rise of Mucormycosis (Black Fungus) tied to Covid treatment. The volume of images indicates the growing demand for this drug in this period.
We also found two surprising clusters of images of Gods and of close up of people’s faces. We tracked the images of people’s faces to a specific spiritual WhatsApp group which had the terms ‘Covid’ and ‘healing’ in the group name. The group aimed to provide healing to Covid patients remotely. The description of the group stated that providing images along with the full name of the patient would result in more effective remote healing. Image clustering helped us identify a specific group that was distinct and possibly not ideal for future data collection. Similarly, we tracked images of God to a specific group which was sometimes used for sharing resources, but was predominantly used for sharing images of different Indians Gods.
Finally, we see clusters of images of news clippings and TV news channels reflecting that these groups were also used to share news related to Covid-19.
What emerged in scanning the different clusters was the predominance of text even in the images. The Instagram, Twitter and Facebook posts, shared on WhatsApp as images, were primarily text posts on the native platforms. Image as a modality emerge as a convenience mechanism to share across platforms. Content from government apps, online dashboards and other social media platforms is given broader reach by sharing screenshots on WhatsApp. This circumvents the need for people to create accounts or access specialized websites. The content contained in these media items is further discussed in the next section.
Textual Analysis
Through the eight week period, we collected 7530 text messages. We retrospectively realized that messages for some days for the first week was missing. We thus discarded text messages from the first week resulting in 6518 messages textual messages being analyzed.
What percent of leads were verified:
Since the second wave, a fact checking group, FactChecker.in, has been upading a list of Covid Helpline numbers it has verified. The fact checking group is sourcing At present the list has 510 ‘verified’ phone numbers38. Ten of these verified numbers were shared in the WhatsApp text messages, and eleven were listed in the images shared on WhatsApp. In total, only 17 unique leads from the Factchecker database were circulated in the WhatsApp conversations39. This means that the majority of phone numbers shared on the WhatsApp groups we were tracking were not verified by FactChecker.in.
The FactChecker.in database however does not list the leads that were checked and turned out to be inaccurate. Thus we are unable to find out how many, if any, inaccurate leads were shared on the groups we were tracking. What we can say with certainty, however, is that the vast majority of phone numbers for medical resources shared on the WhatsApp group were not verified by FactChecker.in. This could mean that either these numbers were not captured in the fact checking group’s verification process, or that the numbers could not be verified.
Leads to External Links:
At least 13% of the messages (882 messages) contained links to other websites. Twitter was the most popular social media in these WhatsApp groups. 34% of all external links (299 messages) contained links to tweets. There were 39 messages with Youtube links and 15 with Instagram links. 81 messages contained links to other WhatsApp chat groups and 11 contained links to Telegram groups.
todo : insert graph number of messages with links
Difference between Text Contained in Images and Text Contained in Text Messages
The image cluster map revealed that a lot of the images were screenshots of textual information from other platforms. We wanted to understand if the images contained similar information as text messages but from different platforms, or if the information shared varied with the modality.
We thus compared the textual content in the images with content of the text messages.
Text BoxGraphical user interface, text, application, email
Description automatically generated
todo : insert imaage side by side of text extraction
Text BoxGraphical user interface, text, application, email
Description automatically generatedWe use Google’s Cloud Vision API to extract text from images. All non-English text was translated to English using a Google Translate API. Figure 5, shows the results of text extracted form images using the Cloud Vision API. The text extraction from images results in some errors, but is reasonably good enough for basic textual analysis.
We then proceeded to compare the text from images and text in the text messages.
Figure 6 and Figure 7 provide a high level summary of the words contained in images and texts. Words such as hospital, patient, available are common to both text messages and images. The word clouds however do allude to the difference in the relative importance of these words between text messages and images. For example, words such as ‘Help’, ‘Need’, ‘Lead’, ‘Contact’, appear prominently in the text messages but not in the text in images. On the other hand, words such as ‘Available’ seem more prominent in images.
todo : wordcloud with hostpital big todo : insert wordclod with patient at top
We further investigated this difference in content of the text contained in images and text using comparative word frequency analysis. We compared the proportion of the thirty most frequent used words in the images with the thirty most frequent words in text messages. The methodology is described in detail in the appendix. Figure 8. shows this comparison.
This comparison shows that while words such as ‘available’, ‘blood’, ‘patient’, ‘oxygen’, had nearly equal representation in images and text messages (close to the y=x line), words such as ‘need’ and ‘help’ were significantly more common in text messages. This indicates that while both text messages and images (which are screenshots of information from other platforms) were used to advertise for availability of Oxygen or blood donors, the request for medical aid was circulated as text messages native to WhatsApp. The word ‘verify’ was also significantly more common in text messages than images.
todo : insert Comparison of Words in Images graph
Variations in Conversation Over Time and Across Groups
The analysis, so far, summarized conversations in twenty one groups across seven weeks. The situation during the second Covid wave in India, however, was changing rapidly. We tried to analyze if the conversations in these groups reflected the changing status of the pandemic. We limited the temporal analysis to the sixteen groups for which we had data for all seven weeks.
To carry out the temporal analysis, we analyzed the prominent words in each of the seven weeks separately. We then used the technique Term Frequency - Inverse Document Frequency (TF-IDF) to contrast the conversations across these seven weeks[1]. Using TF-IDF, we weights the frequency of terms in a specific week against the occurrence of the term across all the weeks. Thus terms that are common across all the weeks are weighted down, highlighting the words that are salient in any specific week.
Figure 9 shows the sixteen words in every week that had the highest frequency after adjusting them against their occurrence across all weeks. The word ‘Oxygen’ stops appearing in the frequent words list after 20th May 2020, reflecting that the need for medical Oxygen had declined by then. In the two week period between 27th May 2020 and 3rd June 2020, we also see words such as ‘Dose 1’, ‘Dose 2’, ‘Cost’, indicative of a spike in conversations around vaccines. By the last week, words such as ‘help’ or ‘need’ become less prominent. Instead, hyperlinks to other WhatsApp groups (reflected by the terms whatsapp, chat, com) emerge as the prominent theme from the last week.
todo : insert table data with 7 columns Similarly, applying TF-IDF across the twenty one groups, highlights the distinctiveness of conversations in each group. In many of the groups, names of Indian cities feature in the list of ten most frequent words, indicating the geographies that the group caters to. One group stood out because the most frequent terms in the group were unrelated to Covid-19.
todo : insert table with 2 columns
Investigating more into this group, we realized that while the group was initially created for Covid relief, it changed into a group for chartered accountancy related information by end of June. The admin of the group was a chartered accountant.
Discussion
The Social Media Mix-and-Match
It is unsurprising that people use multiple social media platforms at once. This analysis however reveals a specific method in which different social media platforms were used in conjunction for relief work. WhatsApp, with 400 million users is the most popular platform in India. Twitter has fewer than 20 million users. Despite the low user base, we see heavy reliance on Twitter, from the analysis of images and text messages. In the specific groups we were tracking, WhatsApp was the primary channel to collect requests for aid, but when it came to advertising availability of resources, people also relied on Twitter and Instagram. Instagram provides a restricted experience for unregistered users. Thus, while we see a big cluster of screenshots of Instagram posts, there are very few direct links to Instagram posts in these conversations. These platforms could emerge as centralized, constantly updating, repositories of information in a way that WhatsApp could not. While information flows on WhatsApp depend on users pushing information, Twitter and WhatsApp also allow for pulling information. This ability to pull information, on demand, is of critical importance in relief work connecting those in need to necessary medical aid.
This analysis also reveals an important role for the ‘go-betweens’ who connect WhatsApp users to information on Twitter and Instagram, giving content on these platforms greater reach than that reflected by the engagement metrics on the platforms.
Extensions of Techniques
Once we have marked certain clusters manually with labels like "Religious Imagery" or "Medical Supplies", the centroid of these clusters could help determine what an newly arrived unknown image is with certain confidence. This could help you automate tasks like ignoring all images that have Religious Imagery or forwarding Images from the Medical Supplies cluster to a medical misinformation management team. You would have to periodically re generate the t-sne map and verify if your clusters are still valid.
Limitations in Analysis
Data Limitations
Extracting Text from Images
Google’s Cloud Vision API or any general-purpose Computer Vision technology is fairly good at extracting text from images. These technologies can handle images with text in various fonts and orientation and hence are quite reliable for extracting images from the kind of memes we see on Indian social media. In our experience they don’t fare as well when extracting text from newspaper clippings with multiple columns, which usually contains distinct sections of texts. These tools often return one big blob of text with no notion of paragraphs and columns.
The text extracted might have coherent bits. But it might not be coherent altogether.
todo : insert dainik jagran pic
One way to remedy this would be to process images detected to be News Clippings using a different algorithm. We could add some preprocessing to these images to separate out different sections of the newspaper while also grouping paragraphs or columns within those sections.
Mixed Code Language
People use multiple languages within the same post. They may also type words from Indian languages in Roman script. Take this snippet from a text message shared on one of the groups:
My father Mr. Kailash Rastogi died yesterday morning i.c. 07-05-2021. He was admitted in GANGASHEEL HOSPITAL Bareilly And i am sure that something fishy happened due to which my father dicd. Kal tak recovery thi... mai unhe discharge krane k liye baat kr ri t... he was continuously saying ki yaha sab mile hue hain... inko paise milte hain... every night they kill people. He wrote in a paper please arrange for oxygen cylinder or else THE END.
We detect for non-English messages by checking if the text contains any characters not in the English. This text, while containing some messages in Hindi, uses the English script. This message, thus is not detected as a non-English message that needs to be tested. Some experimentation with Google translate showed that Google Translate too detects these messages as English language, and does not selectively translate the non-English sentences.
This issue can be managed by breaking down every message into individual sentences and attempting a language detection and translation on each sentence individually. But people may use multiple languages within the same sentence and some sentences may still escape accurate language detection. Finally, even when the language is detected correctly, the automated translation is not always accurate.
todo : insert image side by side of translation
ML used for Anonymization
We used blazeface model from tensorflow.js to detect faces in images and draw black rectangles over them. While it worked well for most cases, it missed out a few faces which we had to manually peruse and anonymize. If one was analyzing an image dataset within a trusted closed environment, this would not be a problem but it prevents the automation of creating a public report like this while adequately protecting privacy of people featured in the images.
Discussion
Covid Healing group
“Hi everyone, pls do post the front picture, location, name and problem faced by the patient, it would be a bit easier for healing. Thanks”
- 7 days is too long in Covid Relief. Consider turning on disappearing messages.
- Proactive admins can make a lot of difference.
- Decentralized debunking has its limits
- Covid relief work has humanized the objects of fact checking.
Appendix
WhatsApp Export Chat Scraper
Similarity Matching and Clustering Algorithm
To be able to search the image dataset for duplicates and redundancy efficiently, we use vector embeddings. Each image is represented as a 512-dimensional vector embedding. These are extracted from the image using a pretrained ResNet model. These vector representations of the images are indexed in ElasticSearch. Similarity between two images can be calculated by using the L2 distance between them. We cluster images by grouping vectors which are at a distance of >=0.9 and <=1.0 from each other.
Language Translation
Anonymization
Image Analysis
What are The Documented Harms
In this section we try to explain what is at stake when low quality information proliferates in spaces with blurred public and private boundaries. We document harms to individuals from being identified on and through these groups, as well as harms from inaccurate and obsolete information. These harms are not unique to information shared through chat apps. However, the storage of communication in device end points (mobile phones) as opposed to centralized servers, demands a different approach in responding to harms on chat apps.
Footnotes
1 : explain the footnote here